Whisper es una herramienta gratuita y software libre que utiliza inteligencia artificial local de nuestros sistemas para reconocer palabras en un archivo de audio y convertirlas a texto (lo que se conoce normalmente como ASR: Automatic Speech Recognizer) y que ha sido desarrollada por los creadores de Dall-E2 y ChatGPT: OpenAI.
Ya conocéis VOSK y vimos sus ventajas y sus inconvenientes, en la mayoría de los casos esta herramienta es más que suficiente para lo que necesita la mayoría que no tenga muchos requisitos. No obstante, cuando apareció Whisper decidimos echarle un vistazo y su resultado nos sorprendió más de lo que pudieramos imaginar. Reconoce nombres, fechas, matrículas, números de ID, y prácticamente cualquier cosa que se dijera, incluso puede reconocer a distintas personas y escribir la conversación como si fuera un guión de una película. Whisper de OpenAI había vuelto a hacerlo aunque no tuviera mucha publicidad de los grandes medios, es una herramienta fabulosa y que merecía la pena probarla en serio.
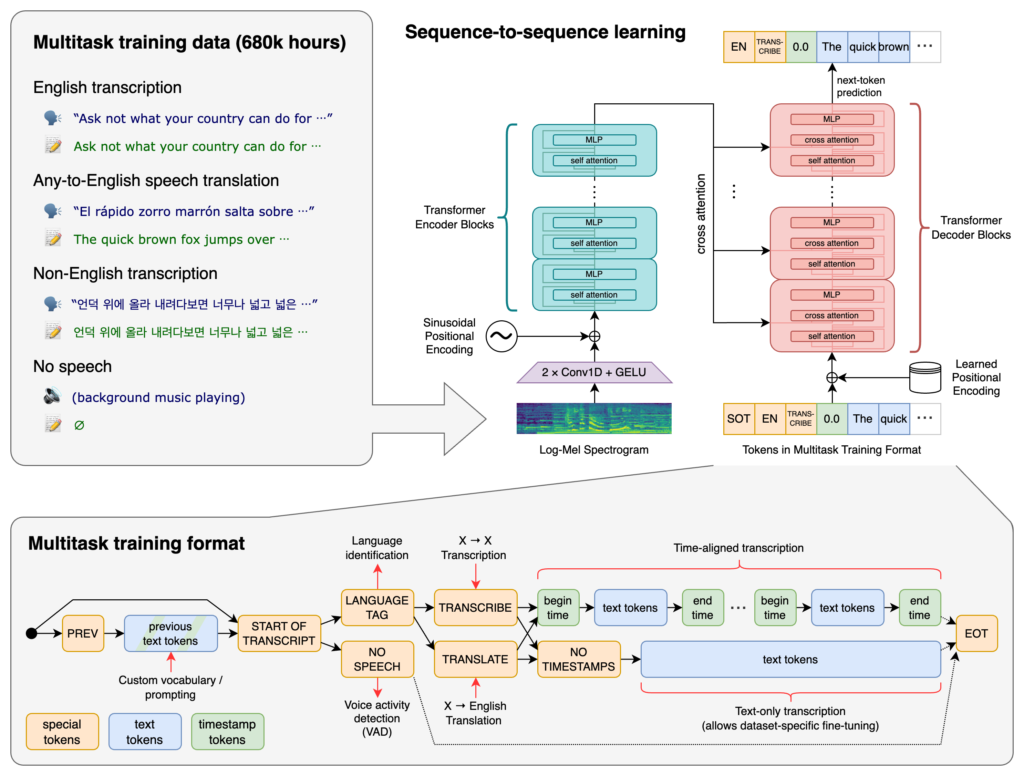
Whisper utiliza como «motor de inteligencia artificial» la librería PyTorch, una librería muy conocida y que, aunque lleva muchos años funcionando, es una de las mejores, aunque como tal, requiere de hardware especial.
Whisper requiere una GPU compatible
Ahí es donde empezamos a pensar en probarla en local y nos encontramos con algo que ya esperábamos: al trabajar con inteligencia artificial requiere de una gran potencia de cálculo, lo que implica que allá donde queramos ejecutarla necesitaba de una GPU (una tarjeta gráfica potente) que soporte CUDA porque sin esto, reconocer 1 minuto de conversación podía llevar más de 2 horas de cómputo.
No obstante, entramos en su web e instalamos Whisper para probarlo en un ordenador con una tarjeta gráfica con CUDA y vemos qué tal funciona y los resultados son espectaculares, además de que, a diferencia de otros servicios de OpenAI, Whisper no requiere de conexiones remotas a servidores externos, por lo que el reconocimiento es local.
Reconocimiento multi-idioma y diferentes modelos
Reconoce prácticamente cualquier idioma: Español, Inglés, Francés, Catalán, Gallego, y 50 idiomas más.
Tiene varios modelos separados en función de la calidad del reconocimiento:
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
Como veis, un reconocimiento mínimo apenas consume 39Mb y 1Gb de RAM, además de ser muy rápido, pero en este caso Vosk es incluso mejor.
Para que Whisper reconozca medianamente bien, el modelo recomendado es small o medium, y con esto, una conversación telefónica podría ser perfectamente reconocida y procesada, mucho mejor que Vosk.
Demo gratuito de Whisper
Como lo mejor es una demo para que lo probéis, aquí hay una web que tiene un procesador especial para probar Whisper remotamente: https://huggingface.co/spaces/anzorq/openai_whisper_stt



Únete a la comunidad Sinologic
Crea tu cuenta gratuita y participa en las conversaciones sobre VoIP, Asterisk, Kamailio y telecomunicaciones IP.
Comparte y aprende
Los comentarios son la mejor parte del blog.