


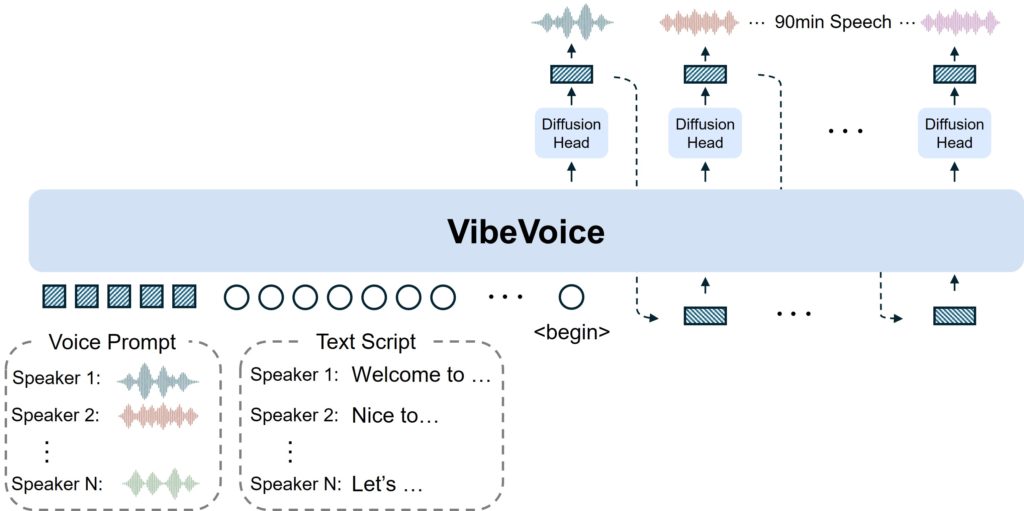
Microsoft acaba de liberar como software libre uno de los mejores TTS para transmisión en tiempo real de audio, un sistema realmente fantástico que consiste en que es capaz de leer un texto en tiempo real casi tan rápido como lo haría una persona de carne y hueso y con una claridad y naturalidad que apenas alguien se daría cuenta que es un software.
Con un modelo de 0.5B de parámetros (lo que permitiría ser ejecutado por una CPU bastante normalita o una GPU básica) el nuevo TTS de Microsoft no sólo está pensado para generar audio con una latencia mínima (lo que mejoraría considerablemente el paso de transcribir el texto generado por un modelo de lenguaje -LLM- a voz) si no que, además, añade cierta naturalidad necesaria en una voz que generalmente suena muy robótica y fría, típica de los agentes.
Este nuevo modelo de TTS se llama VibeVoice y aquí podéis encontrar toda la información: https://microsoft.github.io/VibeVoice/
Y aquí la página de huggingface: https://huggingface.co/microsoft/VibeVoice-Realtime-0.5B
Aquí un ejemplo de cómo se escucharía (por un inglés hablando español xD)
Aunque el modelo tiene varias voces en varios idiomas, el español es uno de ellos, aunque está en modo experimental, tocará investigar cómo probarlo y utilizarlo para sacarle todo el jugo que podamos.
Para algo que Microsoft publica como software libre, merece la pena el esfuerzo.